神经网络
解释
人工神经网络(英语:artificial neural network,ANNs)又称类神经网络,简称神经网络(neural network,NNs),在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统,通俗地讲就是具备学习功能。现代神经网络是一种非线性统计性数据建模(概率模型)工具,神经网络通常是通过一个基于数学统计学类型的学习方法得以优化,所以也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。【以上来自维基百科】
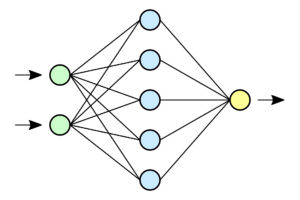
构成
对于某个神经网络,它一般由 输入层(绿色)、隐藏层(蓝色)、输出层(黄色) 构成,而且输入层与输出层的节点数一般是固定的。隐藏层所包含的层数越多、神经元越多,能拟合(预测)的情况就越复杂,然而代价是训练难度也会大大增加。
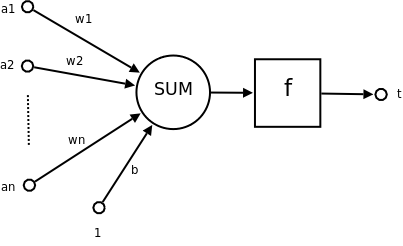
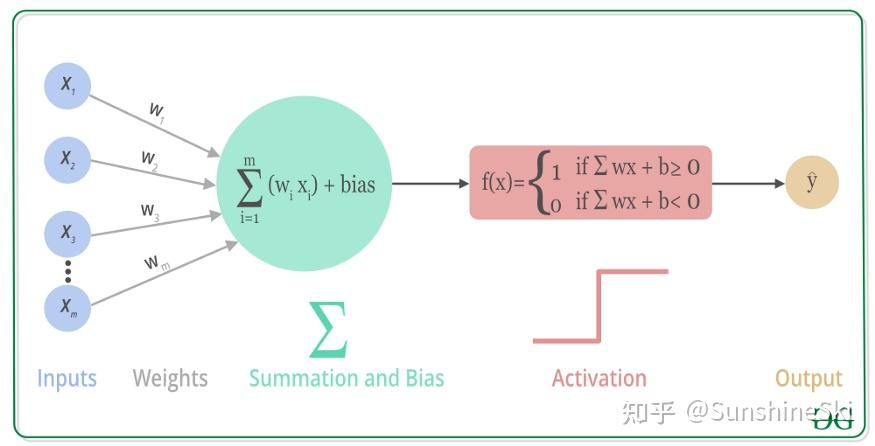
对于每个神经元,它由输入、权重、求和、非线性函数构成,它往往有多个输入值和单个输出值,而它满足:
其中表示第层第个神经元的值,而则表示第层第个神经元的第条连接的权重。
注意
对于有多输出值的神经元,它们的所有输出值是相等的。
神经元的连接是最重要的属性,在神经网络的训练算法中,最重要的内容就是把权重调整到适宜的值,使得预测效果最佳。这样神经网络在输入一个新的值后,能根据调整完成的权重输出较好的预测值。
偏置
对于,它可以理解为一条过原点的直线。从神经元中迁移概念,可见每个神经元都有一个阈值来激活(触发),因此在神经网络中我们也同样引入偏置概念,用来表示,此时有:
这样过原点的直线有了截矩,能够上下移动,这样能提高模型的拟合精度。
激活函数g(x)
我们把叫做,称为净输出值,可以很显然地看出,净输出值是线性的。不过在日常生活中,诸如猫狗分类等一系列问题的结果都应当是非线性的(因为不可能能具体划分一个数值,大于该数值的是猫,小于该数值的是狗)。因此,我们需要对净输出值引入一个激活函数来处理。常见的激活函数有:
这些函数可以对净输出值做处理,获得一个非线性的结果,从而达到更好的激活效果。我们称:,此处的。这样,第层各节点输出值,又被传入第层。
总结
由上面的内容可以了解到,对于每一层神经元,它的实际作用相当于将输入的数据经过一个三元函数处理,最终获得输出值。
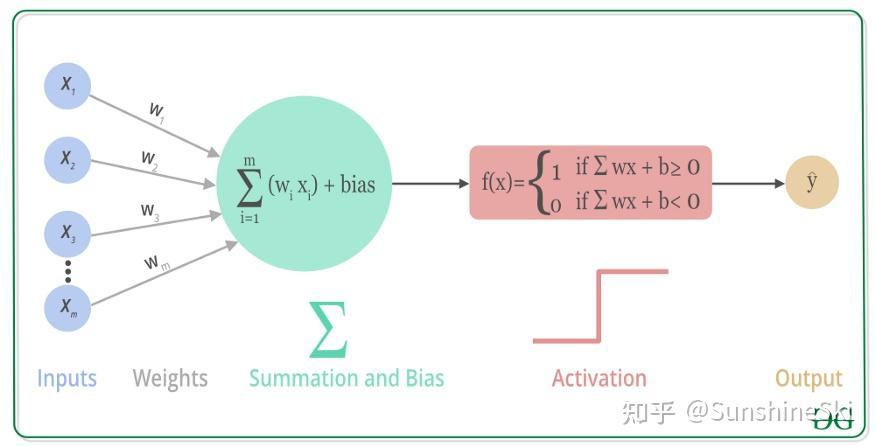
图中的激活函数为简单的sgn(x),取符号函数
传播
前向传播(FP)
从上面所述的过程可见,通过不断地将上一层输出值乘以权重,可以从神经网络的前一层推进到后一层。进一步地,我们发现可以用矩阵乘法来表示:
这样我们可以通过输入层一层一层向前推进,从而最终根据现有的权重推导出输出层,而这个过程就叫做前向传播。
提示
由构成的矩阵叫做权重矩阵(参数矩阵)
后向传播(BP)
那么问题来了,仅仅是前向传播如何能在训练中更新权重呢?于是我们要引入后向传播来检验和调整。后向传播的作用就是根据最终输出值与真实值的差异,反向更新参数矩阵,使结果能更好拟合。首先我们要引入一个损失函数:
上面以二次损失函数为例子
反向传播算法的核心是代价函数对网络中参数(各层的权重和偏置)的偏导。这些表达式描述了代价函数值随权重或偏置变化而变化的程度。而显然,我们为了模型较好的拟合,要让代价函数的值尽可能小,所以就可以通过调整偏导数中的参数来实现,具体的数学过程此处就不展开了。

